Google Plans to Capture the Inference Market with IronWood
Ironwood is Google’s seventh-generation TPU (Tensor Processing Unit)

Google has introduced Ironwood, the latest generation of its custom AI accelerator chip.
Announced at its Cloud Next conference this week, Ironwood is Google’s seventh-generation TPU (Tensor Processing Unit) and marks a major shift — it’s the first TPU designed specifically for inference, the process of running and deploying AI models, rather than just training them.
"Ironwood represents a significant shift in the development of AI and the infrastructure that powers its progress. It’s a move from responsive AI models that provide real-time information for people to interpret, to models that provide the proactive generation of insights and interpretation. This is what we call the age of inference where AI agents will proactively retrieve and generate data to collaboratively deliver insights and answers, not just data," Google said in a blog post.
Ironwood is designed to meet the growing demands of generative AI, offering the high-performance computing and communication capabilities required at scale. The system can scale up to 9,216 liquid-cooled chips, connected through Google’s advanced Inter-Chip Interconnect (ICI) network, operating across nearly 10 megawatts of power.
It’s a key part of the Google Cloud AI Hypercomputer architecture, which tightly integrates hardware and software to handle the most intensive AI workloads. With Ironwood, developers can tap into Google’s Pathways software stack, making it easier to coordinate and harness the power of tens of thousands of TPUs for large-scale AI applications.
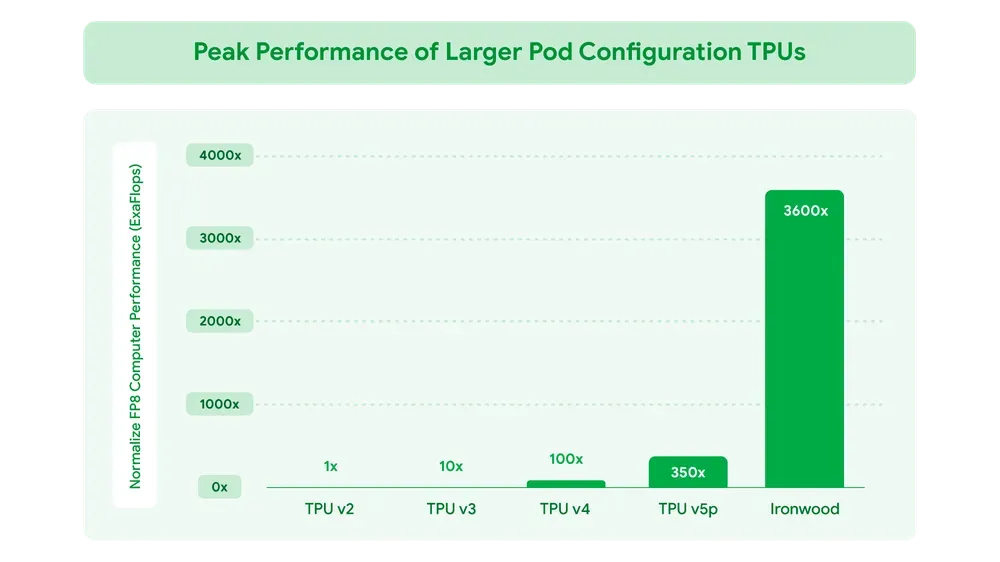
Set to roll out later this year to Google Cloud customers, Ironwood will be available in two configurations: a compact 256-chip cluster and a powerful 9,216-chip cluster, offering scalable performance for a range of AI workloads.
At full scale, it offers 42.5 exaflops—over 24 times more compute than the world’s top supercomputer. Each chip delivers 4,614 TFLOPs, supporting ultra-large LLMs and MoE models. Ironwood features 192 GB of HBM, 7.2 Tbps memory bandwidth, and 1.2 Tbps interconnect, ensuring rapid data access and efficient parallel computing.
The enhanced SparseCore supports advanced recommendation and scientific workloads. With 2x the power efficiency of its predecessor and seamless integration via the Pathways runtime, Ironwood redefines scalable, sustainable generative AI infrastructure.



